Support Vector Algorithm in Machine Learning
In the realm of machine learning, algorithms play a vital role in solving complex problems and making intelligent decisions. One such powerful algorithm is the Support Vector Machine (SVM). SVM is a supervised learning algorithm that excels in both classification and regression tasks. Its ability to handle high-dimensional data and complex decision boundaries makes it a valuable tool in various domains. In this article, we will delve into the details of the Support Vector Algorithm, its working principles, and the key concepts behind it.
Understanding Support Vector Machines
Support Vector Machines (SVM) are a class of algorithms that perform classification by finding the optimal hyperplane that separates the data points belonging to different classes. Unlike other algorithms that aim for a simple linear separation, SVM seeks to maximize the margin between the support vectors, which are the data points closest to the decision boundary. This approach makes SVM robust to noise and leads to better generalization.
Working Principle of SVM
The primary goal of SVM is to find a hyperplane that maximizes the margin between the support vectors of different classes. The margin is defined as the distance between the hyperplane and the nearest data points from each class. The SVM algorithm aims to find the hyperplane that achieves the maximum margin while ensuring that the data points are correctly classified.
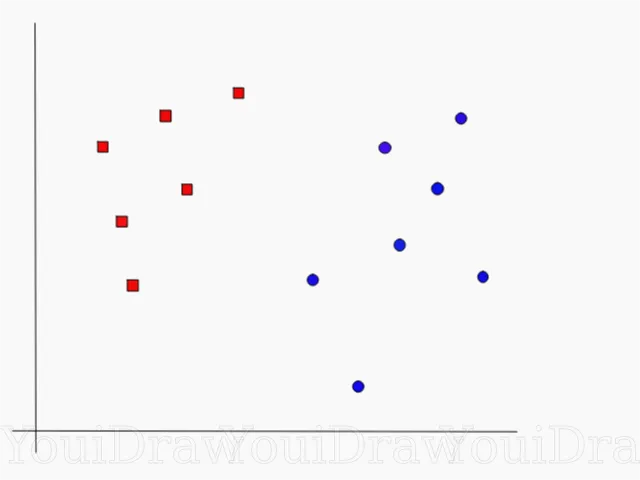
To understand this, let’s consider a simple binary classification scenario with two classes: Class A (represented by blue circles) and Class B (represented by red squares). Here’s a graph illustration of the data points:

In this case, the data is not linearly separable, meaning we cannot draw a straight line that perfectly separates the two classes. SVM addresses this by mapping the data into a higher-dimensional feature space using a kernel function. The most commonly used kernel is the Radial Basis Function (RBF) kernel.
Mathematically, the hyperplane can be represented as:
w·x + b = 0
where w represents the weight vector perpendicular to the hyperplane, x is the input vector, and b is the bias term. The classification of a new data point is determined by evaluating which side of the hyperplane it lies on.
To find the optimal hyperplane, SVM transforms the input data into a higher-dimensional feature space using a kernel function. This allows SVM to find nonlinear decision boundaries in the original input space. Some commonly used kernel functions include the linear kernel, polynomial kernel, and radial basis function (RBF) kernel.

Key Concepts of SVM
- Margin: The margin represents the separation between the hyperplane and the support vectors. SVM aims to maximize this margin to improve the model’s robustness.
- Support Vectors: Support vectors are the data points closest to the decision boundary. They play a crucial role in defining the optimal hyperplane and the margin.
- Kernel Trick: The kernel trick is a technique used by SVM to map the data into a higher-dimensional space without explicitly calculating the coordinates. It allows SVM to find complex decision boundaries.
- Regularization Parameter ©: The regularization parameter, C, controls the trade-off between maximizing the margin and minimizing the training error. A higher C value gives more importance to classifying all training examples correctly, potentially leading to overfitting.
Advantages of SVM
- Effective in high-dimensional spaces: SVM performs well even when the number of features exceeds the number of samples. This makes it suitable for various applications, such as image classification and text categorization.
- Robust to noise: The use of margins and support vectors in SVM helps to create a decision boundary that is less affected by noisy data points, enhancing the model’s generalization capability.
- Versatility: SVM can handle both linear and nonlinear decision boundaries through the use of different kernel functions.
- Ability to handle large datasets: SVM’s computational efficiency is maintained even when dealing with large datasets due to the subset of support vectors that define the decision boundary.
Understanding the working principles and key concepts of SVM empowers machine learning practitioners to harness its full potential. SVM’s ability to handle high-dimensional data, robustness to noise, and versatility in handling both linear and nonlinear decision boundaries make it a valuable tool in various domains. Whether it’s image classification, text categorization, or other complex tasks, SVM provides an effective solution.
However, it’s important to note that SVM’s performance heavily depends on the appropriate selection of kernel functions and regularization parameters. Careful tuning and cross-validation techniques are essential to achieve optimal results. Additionally, SVM may face challenges in scaling to extremely large datasets due to its memory requirements.
Nonetheless, the Support Vector Algorithm remains a fundamental and widely-used method in machine learning, with numerous extensions and variations that continue to advance its capabilities. As researchers and practitioners explore new approaches and innovations, SVM continues to serve as a reliable and powerful tool in the ever-evolving field of machine learning.

{kind=link}
{kind=link}